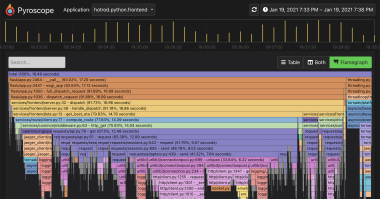
Predictive CPU isolation of containers at Netflix ( netflixtechblog.com )


This magazine is from a federated server and may be incomplete. For a complete list of posts, browse on the original instance.

My kernels go 2x faster than MKL for matrices that fit in L2 cache, which makes them a work in progress, since the speedup works best for prompts having fewer than 1,000 tokens.




ULL trading firms go to a lot of trouble to get their servers and switches within the same buildings as the exchanges they trade with to reduce latency. Some firms don’t even use layer 1 switches to be competitive.